|
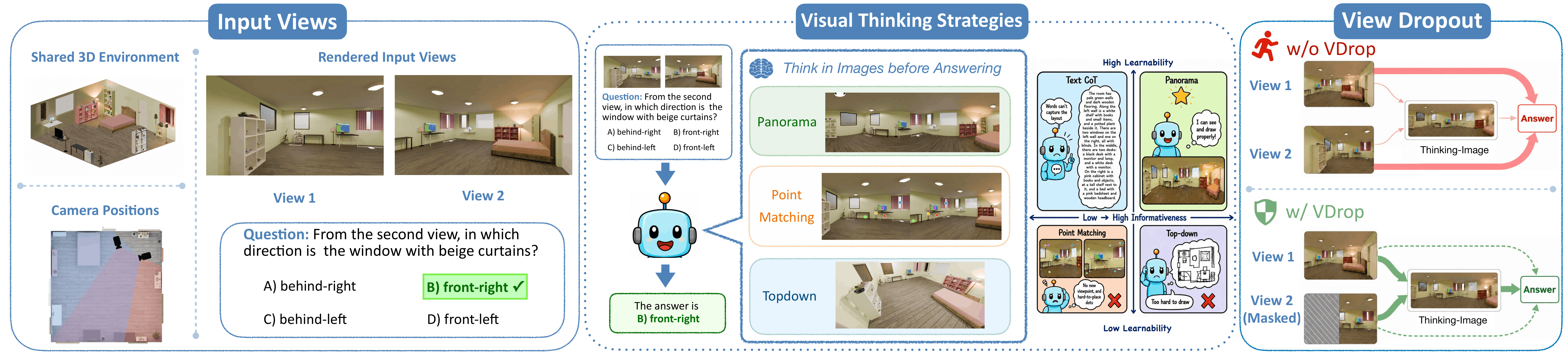
How and What to Imagine? Visual Thinking in Unified Multimodal Models for Cross-View Spatial Reasoning arXiv 2026arXiv |
Publications
For the up-to-date publication list, please visit the Google Scholar page.
Filter by type:
(*) denotes equal contribution
2026
|
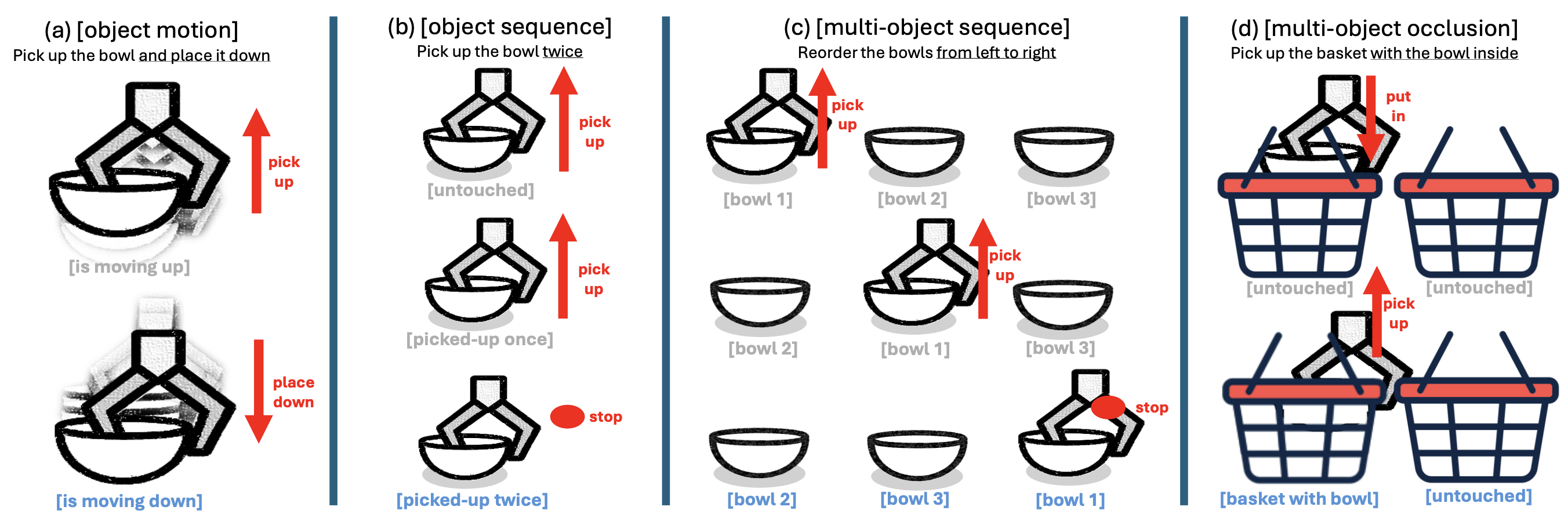
SlotVLA: Towards Modeling of Object–Relation Representations in Robotic Manipulation ICRA, 2026arXiv Project Page Code |
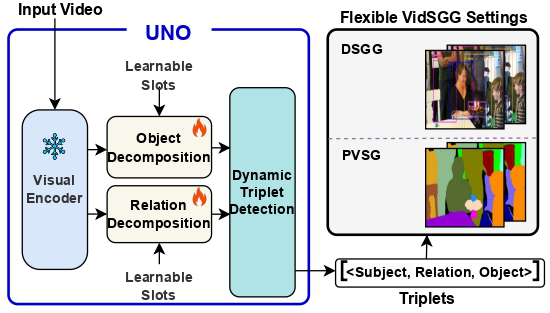
2025

2024
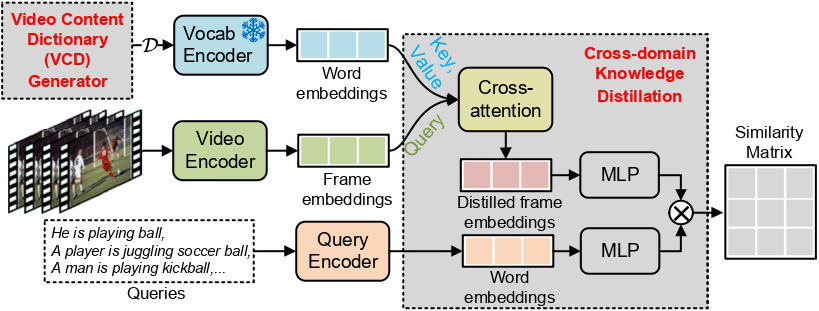
2023
|
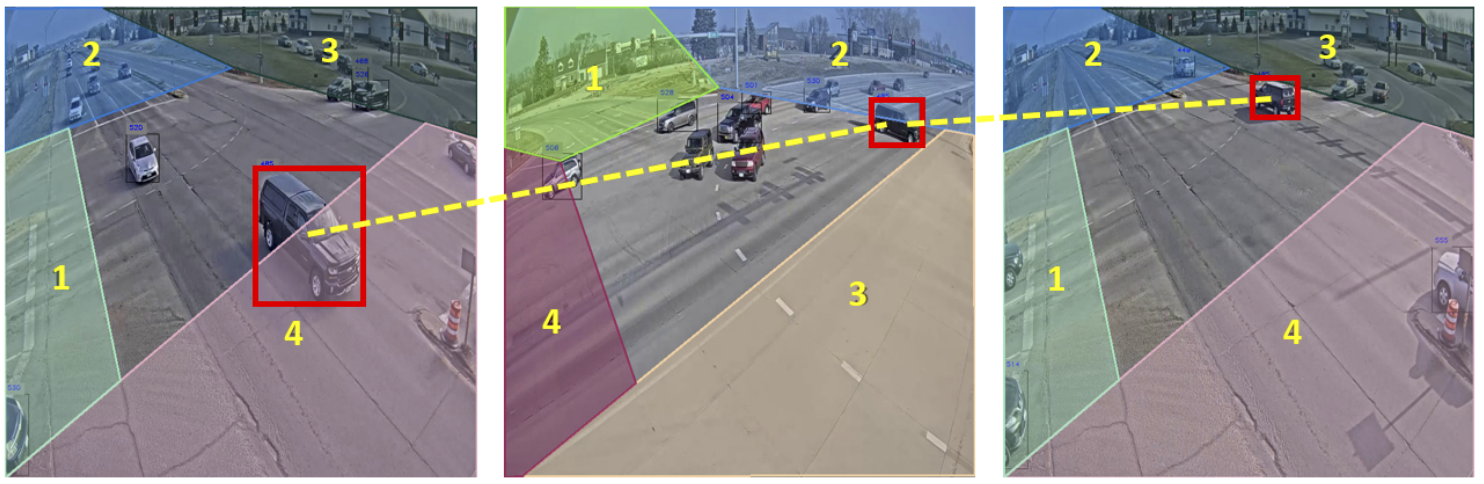
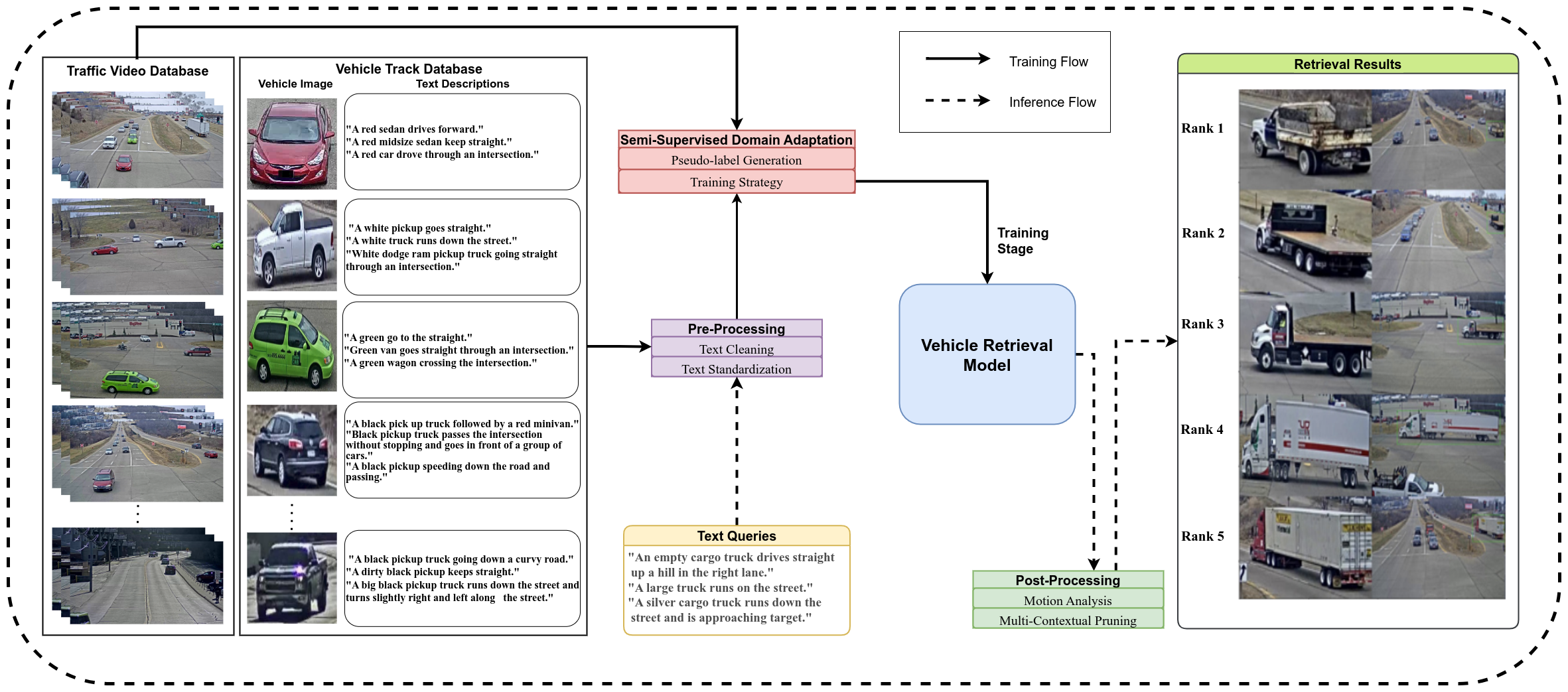
Tracked-Vehicle Retrieval by Natural Language Descriptions With Multi-Contextual Adaptive Knowledge CVPR Workshop 2023Track 2 - Winner Award🏆, The 7th AI City Challenge Workshop PDF Code |
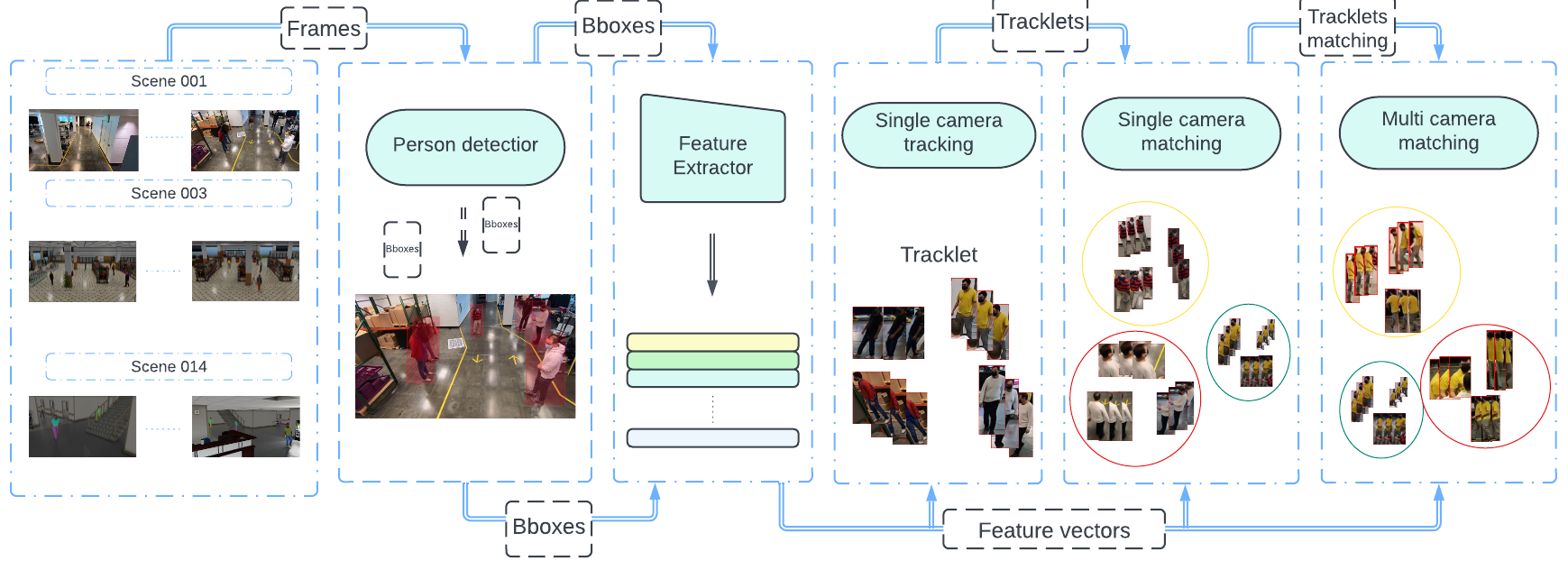
|
Multi-camera People Tracking With Mixture of Realistic and Synthetic Knowledge CVPR Workshop 2023Track 1 - Runner-up Award🥈, The 7th AI City Challenge Workshop PDF Code |